State Machine Replication, Leader Follower ve Consensus Konseptleri
STATE MACHINE REPLICATION
State machine replication dağıtık sistemlerde kullanılan bir yöntemdir. Bu yöntemde, bir grup işlemci veya process, aynı inputları aynı sırayla işleyerek ve aynı sonuçları üreterek, birbirleriyle eşitlenen bir durum makinesini taklit eder. Yani, her process aynı komutları aynı sırada çalıştırır ve böylece her biri aynı durumda kalır. Bu sayede, sistemdeki herhangi bir faulty process’e karşı direnç sağlanır ve reliability artırılır. State machine replication, sistemdeki her processin aynı inputları aynı şekilde işlemesini sağlayarak, sistemdeki farklı bileşenler arasında consistency ve reliability sağlar.
LEADER & FOLLOWER YAPISI
Leader-follower yapısı, dağıtık sistemdeki processler arasında lider ve takipçi rolleri arasında bir ayrım yapar. Bir lider process diğerlerine liderlik ederken, takipçi süreçler liderin yönlendirmelerini takip eder. Bu lider-takipçi ilişkisi, sistemdeki iş yükünü daha dengeli dağıtmak ve yönetim görevlerini etkin bir şekilde yerine getirmek için kullanılır.
Bu bağlamda, leader-follower yapısı, state machine replication’ı desteklemek için kullanılabilir. Lider süreç, gelen inputları alır, bunları takipçi süreçlere yönlendirir ve durum güncellemelerini koordine eder. Takipçi süreçler, liderin yönlendirmelerini takip ederek aynı inputları işler ve durumlarını günceller. Böylece, leader-follower yapısı, state machine replication’da processler arasında görev dağılımını sağlar ve güncel durum makinesini korur.
Tanımlardan sonra konuyu biraz daha detaylandıralım. Dağıtık bir data storage düşünün. Replike olmuş 4 adet node olsun. Bu processler bir birinin replikası olduğu için belli bi noktaya kadar inconsistency olsa da en nihayetinde aynı dataları sunabiliyor olmaları gerekir. Bu noktada storage’a yeni bir data eklediğinizde ya da güncellediğinizde diğer replikaların da bu güncellemeyi almasını beklersiniz. Ancak, bu yazma işlemini rastgele herhangi bir node’a yapabiliyor olmamız belli karmaşıklıkları yanında getirir. Örneğin hangi node’lar hangi node’lardan güncellemeyi alacak ya da okumayı hangi node’dan yapacağız ki tutarlılık sistematik olsun. Dolayısıyla bu gibi endişeler göz önünde bulundurulduğunda dağıtık sistemlerde bir hiyerarşi olması şarttır ve sistemlerde bir processin belli yönetim işlerini üstlenmesi gerekir. Bu da process de leader olarak adlandırılır. Leader replicated systemdeki state’i değiştirme yetkisine sahip tek process’tir. Bunu da state’i değişterecek operasyon’ları local log’una yazarak yapar. Yani aslında dağıtık bir storage’a write ya da update yaptığınızda bu direkt olarak işlenmez önce log’ta tutulur. Bu logları da followerlar replike olmak için kullanır. Yani replike edilmiş loglar replicated sistemin tutarlı olmasını sağlar.
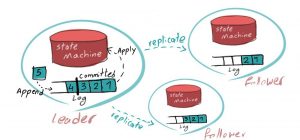
Neden bu log sistemine ihtiyaç var biraz bunun detaylarına girelim. Diyelim ki bir write ya da update işlemini yaptınız. Leader olan process de bunu kendi state’ine uygulayacak. Leader kendi local state’ine bir operasyon uygulamak istediğinde, başlangıçta da söylediğim gibi önce bunu local loguna yazar. Daha sonra tüm followerlara AppendEntries adında bir request gönderir. Bu request yeni eklenecek bir entry olmasa bile periodik olarak gönderilir. Çünkü bu request aynı zamanda leader için followerların stateini takip eden bir heartbeat olarak da davranır. Bir follower da AppendEntries requestini aldığında, aynı şekilde ilk olarak kendi loguna yazar ve leader’a log’a yazma operasyonun başarılı olduğununa dair acknowledge gönderir. Leader followerları çoğunluğundan log’a yazma işleminin başarılı olduğunun ack responseunu aldığında kendi tarafında entryi commit eder ve operasyonu local stateinde execute eder. Artık bu noktada leader’in statei güncellenmiş yani yaptığınız write/update işlemi geçerli olmuştur diyebiliriz. Followerlar ise leaderin commit ettiği entryi, kendi log entrylerinden local statelerine geçirirler.
Log sıralı entryler listesidir ve içerisinde
- State’e uygulanan operasyonları (örneğin x’e 3 ü ata.) barındırır. Bu operasyonlar tüm followerların aynı state’te sonlanabilmesi yani nihayi sonuca ulaşabilmesi için deterministik olmalıdır.
- Entryinin logtaki pozisyonunun indexi
- Ve kutuların içerisinde olan leader election termini içerir.

Bu yapının altında yatan sebep şudur. Leader followerların coğunluğundan yanıt alamadan hareket edemez. Leaderin ve ardından followerların elindeki operasyonu commit etmesi için leaderin followerların yarısından 1 fazla ack alması gerekir. Aksi durumda rollback olup data loss olacaktır.
Bu noktaya kadar her şeyin yolunda çalıştığını varsayarak ilerledik. Eğer leader down olursa, followerlar arasından yeni bir leader election yapılır. Leader replikasyon algoritması için processlerin en az yarısından fazlası ayakta olmalıdır. Ayrıca up to date olmayan followerların leader olma ihtimalini ortadan kaldırmak için electiona dahil edilmezler, oy alamazlar ve oy kullanamazlar çünkü up to date olmayan processler’in, güncel olmayan bilgilere dayalı olarak bir lider adayını değerlendirmesi ve oy kullanması, election’un doğruluğunu ve adil olmasını tehlikeye atabilir. Yani process tüm commitleri almadıysa electionu kazanması mümkün değildir. Up to date processleri belirlemek için log entrylerinin sonuncusunun indexine bakılır. Index countı yüksek olan up to date olarak kabul edilir.
Bir AppendEntries isteği bir veya daha fazla followera teslim edilemezse, leader takipçilerin çoğu bunu local loglarına başarılı bir şekilde ekleyene kadar süresiz olarak göndermeyi yeniden deneyecektir. AppendEntries istekleri idempotent olduğundan ve followerlar, loglarına zaten eklenmiş olan istekleri yok saydığından, yeniden denemelerin side effecti yoktur. Bu noktada bir follower bir sebepten down olduğunda, ayağa tekrar kalktığı zaman AppendEntries ile güncellemeleri tekrar alacaktır.
CONSENSUS
Dağıtık sistemlerde her process bir değer üzerinde uzlaşmalı ki tutarlılık olsun. Bu sürece Consensus adı verilir. Bu anlaşma ve tutarlılık sürecinde aşağıdaki şartların sağlanması gerekiyor:
- Non-faulty olmayan her process sonunda bir değer üzerinde anlaşmalı.
- Non-faulty olmayan her process’in nihai uzlaştığı kararı her yerde aynı olmalı.
- Uzlaşılan değer bir process tarafından önerilmelidir.
Consensus konseptinin uygulamada birçok örneği vardır. Örneğin, tüm dağıtık sistem processlerinin store ettiği tek bir değerde uzlaşması, state machine replication konsepti, leader election gibi tüm konular consensus içerektedir. Leader election’da tüm ayakta olan processler tek bir leader seçmeli ve bu liderde uzlaşıp bu lideri tanımalı. Bu lider düştüğünde aynı şekilde yerine yeni lider seçebilmeli. Böyle bir consensus sistemi lease manager, coordination service ve fault tolerance gibi özelliklere sahip olmalı. İşin iyi tarafı çoğumuz için consensus yapısını sıfırdan implemente etmeye hiç bir zaman gerek olmayacak. Çünkü bunun için çok fazla yaygın kullanılan yapılar mevcut.


Çok yararlı bi yazı olmuş hocam teşekkür ederim .Sizin yazılarınızı beğenerek okuyorum elinize sağlık.